多线程学习4 cpu架构
Contents
关于smp,numa,mpp网上一搜都有
NUMA
|
|
除非硬件具有> 1个PHYSICAL CPU(不是内核而是物理处理器),否则禁用NUMA(由此非延迟端点衡量)是有利的。1 自从Haswell以来,NUMA对于“单处理器”(即单插槽)计算机不再有用。某些Haswell产品具有Intel所说的“ Cluster on Die”模式。单个插槽处理器具有集成的多个内存控制器,因此具有多个内存路径,具有此功能的路径可被视为不同的NUMA区域,所有这些区域都包含一个插槽。2
NUMA出现的原因
单个物理cpu中的所有CPU Core都是通过共享一个北桥来读取内存,随着核数如何的发展,北桥在响应时间上的性能瓶颈越来越明显。于是,聪明的硬件设计师们,想到了把内存控制器(原本北桥中读取内存的部分)也逐个拆分,平分到了每个die上。于是NUMA就出现了!3
目前的理解:所以本质是一根总线读内存在核心越来越多的情况下,响应时间的问题越来越突出,通过增加物理cpu数量(NUMA中称为节点node),使得读内存的总线数也相应增加:
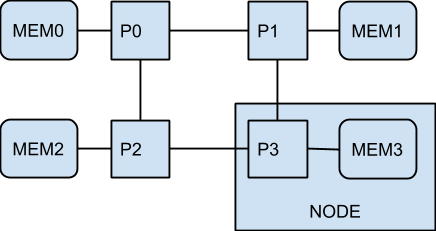 P0 <-> MEM0之间的延迟最小。
P0 <-> MEM1和P0 <-> MEM2之间的等待时间较长;
P0 <-> MEM3之间的等待时间甚至更长。
此非统一内存体系结构(NUMA)规定了对空间局部性的需求。4
erlang的beam和golang的调度所实现的并发目前都是针对smp架构的
P0 <-> MEM0之间的延迟最小。
P0 <-> MEM1和P0 <-> MEM2之间的等待时间较长;
P0 <-> MEM3之间的等待时间甚至更长。
此非统一内存体系结构(NUMA)规定了对空间局部性的需求。4
erlang的beam和golang的调度所实现的并发目前都是针对smp架构的
NUMA对于具有多个CPU插槽(而不是一个插槽中的多个内核)和专用物理内存访问通道(而不仅仅是一个内存控制器)的昂贵服务器非常重要,因此每个CPU都有其专用的本地内存,与它“更近”而不是其他CPU的内存。(请考虑使用8个插槽,64核,256 GB RAM。)NUMA表示,CPU不仅可以访问其自身的本地内存,而且还可以访问远程内存(另一个CPU的本地内存),尽管成本更高。NUMA是共享内存体系结构(例如SMP)和分布式内存体系结构(例如,MPP)的综合体,其中SMP共享所有内存对所有内核均可用,MPP(大规模并行处理)为每个节点提供专用的内存块。它是MPP,但对于应用程序来说看起来像SMP。
台式机主板没有双插槽,包括极速i7版本在内的Intel台式机CPU缺少用于双插槽配置的附加QPI链接。
查看Wikipedia QPI文章以了解QPI与NUMA的关系:
在单处理器主板上,最简单的形式是使用单个QPI将处理器连接到IO集线器(例如,将Intel Core i7连接到X58)。在体系结构更复杂的情况下,单独的QPI链接对连接主板上网络中的一个或多个处理器以及一个或多个IO集线器或路由集线器,从而允许所有组件通过网络访问其他组件。与HyperTransport一样,QuickPath体系结构假定处理器将具有集成的内存控制器,并启用非统一的内存访问(NUMA)体系结构。
参考
1:https://bugs.archlinux.org/task/31187
2:https://qastack.cn/unix/92302/enabling-numa-for-intel-core-i7
3:http://cenalulu.github.io/linux/numa/
4:https://docs.google.com/document/u/0/d/1d3iI2QWURgDIsSR6G2275vMeQ_X7w-qxM2Vp7iGwwuM/pub
Author sorvik
LastMod 2020-07-30